Applying SPARK to the ST datasets segmented by different methods
[1]:
set.seed(20240709)
library(SPARK)
library(ggplot2)
library(tidyverse)
max_cores <- 36
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ lubridate 1.9.4 ✔ tibble 3.2.1
✔ purrr 1.0.4 ✔ tidyr 1.3.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
[2]:
DATA_PATH <- "/import/home/share/zw/pql/data/breast_cancer"
RESULT_PATH <- "/import/home/share/zw/pql/results/breast_cancer"
if (!dir.exists(RESULT_PATH)) {
dir.create(RESULT_PATH, recursive = TRUE)
}
Cells segmented by the 10x method
[3]:
# seg_method <- "Cell_10X"
# counts <- as.data.frame(readr::read_csv(
# file.path(DATA_PATH, "rawdata", seg_method, "counts.csv")
# ))
# rownames(counts) <- counts[, 1]
# counts[, 1] <- NULL
# # head(counts)
# coordinates <- as.data.frame(readr::read_csv(
# file.path(DATA_PATH, "rawdata", seg_method, "coordinates.csv")
# ))
# rownames(coordinates) <- coordinates[, 1]
# coordinates[, 1] <- NULL
# # head(coordinates)
# scvi_labels <- as.data.frame(readr::read_csv(
# file.path(DATA_PATH, "rawdata", seg_method, "scvi_labels.csv")
# ))
# rownames(scvi_labels) <- scvi_labels[, 1]
# scvi_labels <- scvi_labels[, 2]
# # head(scvi_labels)
# all_celltypes <- unique(scvi_labels)
[4]:
seg_method <- "Cell_10X"
myRCTD <- readRDS(file.path(RESULT_PATH, seg_method, "myRCTD.rds"))
spot_names <- colnames(myRCTD@spatialRNA@counts)
counts <- t(as.matrix(myRCTD@originalSpatialRNA@counts[, spot_names]))
# head(counts)
coordinates <- myRCTD@spatialRNA@coords
# head(coordinates)
celltypes_RCTD <- myRCTD@results$results_df$first_type
names(celltypes_RCTD) <- spot_names
# head(celltypes_RCTD)
all_celltypes <- levels(celltypes_RCTD)
[5]:
pvalues_10x <- data.frame()
for(celltype_k in all_celltypes) {
celltype_idx <- which(celltypes_RCTD == celltype_k)
counts_k <- counts[celltype_idx, ]
coordinates_k <- coordinates[celltype_idx, ]
spark_obj <- CreateSPARKObject(
counts = t(counts_k), location = coordinates_k
)
spark_obj@lib_size <- apply(spark_obj@counts, 2, sum)
spark_obj <- spark.vc(
spark_obj,
covariates = NULL, lib_size = spark_obj@lib_size,
num_core = max_cores, verbose = FALSE
)
spark_obj <- spark.test(spark_obj, check_positive = TRUE, verbose = FALSE)
pvalues_10x <- rbind(
pvalues_10x,
data.frame(
celltype = celltype_k,
gene = rownames(spark_obj@res_mtest),
pvalue = spark_obj@res_mtest[, "combined_pvalue"]
)
)
}
saveRDS(pvalues_10x, file.path(RESULT_PATH, seg_method, "pvalues_SPARK.rds"))
# pvalues_10X <- readRDS(file.path(RESULT_PATH, seg_method, "pvalues_SPARK.rds"))
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 5405
## number of total features: 194
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 1291
## number of total features: 177
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 523
## number of total features: 181
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 1515
## number of total features: 148
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 985
## number of total features: 138
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 1442
## number of total features: 123
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 862
## number of total features: 123
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 2062
## number of total features: 124
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 693
## number of total features: 160
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 959
## number of total features: 183
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 288
## number of total features: 164
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 1275
## number of total features: 124
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 487
## number of total features: 166
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 66
## number of total features: 171
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 24
## number of total features: 157
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 40
## number of total features: 160
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 395
## number of total features: 153
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
Cells segmented by UCS
[6]:
# seg_method <- "UCS_10X"
# counts <- as.data.frame(readr::read_csv(
# file.path(DATA_PATH, "rawdata", seg_method, "counts.csv")
# ))
# rownames(counts) <- counts[, 1]
# counts[, 1] <- NULL
# # head(counts)
# coordinates <- as.data.frame(readr::read_csv(
# file.path(DATA_PATH, "rawdata", seg_method, "coordinates.csv")
# ))
# rownames(coordinates) <- coordinates[, 1]
# coordinates[, 1] <- NULL
# # head(coordinates)
# scvi_labels <- as.data.frame(readr::read_csv(
# file.path(DATA_PATH, "rawdata", seg_method, "scvi_labels.csv")
# ))
# rownames(scvi_labels) <- scvi_labels[, 1]
# scvi_labels <- scvi_labels[, 2]
# # head(scvi_labels)
# all_celltypes <- unique(scvi_labels)
[7]:
seg_method <- "UCS_10X"
myRCTD <- readRDS(file.path(RESULT_PATH, seg_method, "myRCTD.rds"))
spot_names <- colnames(myRCTD@spatialRNA@counts)
counts <- t(as.matrix(myRCTD@originalSpatialRNA@counts[, spot_names]))
# head(counts)
coordinates <- myRCTD@spatialRNA@coords
# head(coordinates)
celltypes_RCTD <- myRCTD@results$results_df$first_type
names(celltypes_RCTD) <- spot_names
# head(celltypes_RCTD)
all_celltypes <- levels(celltypes_RCTD)
[8]:
pvalues_UCS <- data.frame()
for(celltype_k in all_celltypes) {
celltype_idx <- which(celltypes_RCTD == celltype_k)
counts_k <- counts[celltype_idx, ]
coordinates_k <- coordinates[celltype_idx, ]
spark_obj <- CreateSPARKObject(
counts = t(counts_k), location = coordinates_k
)
spark_obj@lib_size <- apply(spark_obj@counts, 2, sum)
spark_obj <- spark.vc(
spark_obj,
covariates = NULL, lib_size = spark_obj@lib_size,
num_core = max_cores, verbose = FALSE
)
spark_obj <- spark.test(spark_obj, check_positive = TRUE, verbose = FALSE)
pvalues_UCS <- rbind(
pvalues_UCS,
data.frame(
celltype = celltype_k,
gene = rownames(spark_obj@res_mtest),
pvalue = spark_obj@res_mtest[, "combined_pvalue"]
)
)
}
saveRDS(pvalues_UCS, file.path(RESULT_PATH, seg_method, "pvalues_SPARK.rds"))
# pvalues_UCS <- readRDS(file.path(RESULT_PATH, seg_method, "pvalues_SPARK.rds"))
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 3601
## number of total features: 169
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 1141
## number of total features: 163
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 564
## number of total features: 170
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 1669
## number of total features: 145
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 1184
## number of total features: 126
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 1498
## number of total features: 123
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 870
## number of total features: 120
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 2096
## number of total features: 119
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 773
## number of total features: 141
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 953
## number of total features: 164
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 378
## number of total features: 126
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 1251
## number of total features: 123
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 656
## number of total features: 144
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 71
## number of total features: 147
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 27
## number of total features: 166
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 48
## number of total features: 143
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
## ===== SPARK INPUT INFORMATION ====
## number of total samples: 421
## number of total features: 150
## number of adjusted covariates: 0
# fitting count-based spatial model under the null hypothesis ...
## testing Gaussian kernel: 1...
## testing Periodic kernel: 1...
## testing Gaussian kernel: 2...
## testing Periodic kernel: 2...
## testing Gaussian kernel: 3...
## testing Periodic kernel: 3...
## testing Gaussian kernel: 4...
## testing Periodic kernel: 4...
## testing Gaussian kernel: 5...
## testing Periodic kernel: 5...
Comparsion of the cell-type-specific SVG identification results
[9]:
# pvalues_10x <- readRDS(
# file = file.path(
# RESULT_PATH, "Cell_10X", "pvalues_SPARK.rds"
# )
# )
# pvalues_UCS <- readRDS(
# file = file.path(
# RESULT_PATH, "UCS_10X", "pvalues_SPARK.rds"
# )
# )
[10]:
log10p_lim <- 17 # 5.55e-17
pvalues_10x$minus_log10_pvalue <- -log10(pvalues_10x$pvalue)
pvalues_10x$minus_log10_pvalue[pvalues_10x$minus_log10_pvalue > log10p_lim] <- log10p_lim
pvalues_UCS$minus_log10_pvalue <- -log10(pvalues_UCS$pvalue)
pvalues_UCS$minus_log10_pvalue[pvalues_UCS$minus_log10_pvalue > log10p_lim] <- log10p_lim
pvalues_all <- merge(
pvalues_10x,
pvalues_UCS,
by = c("celltype", "gene"),
suffixes = c("_10x", "_UCS")
)
dim(pvalues_all)
head(pvalues_all)
- 2387
- 6
| celltype | gene | pvalue_10x | minus_log10_pvalue_10x | pvalue_UCS | minus_log10_pvalue_UCS | |
|---|---|---|---|---|---|---|
| <chr> | <chr> | <dbl> | <dbl> | <dbl> | <dbl> | |
| 1 | B Cells | ACTA2 | 3.488987e-01 | 0.4573006 | 0.005374671 | 2.26964811 |
| 2 | B Cells | ACTG2 | 9.802785e-05 | 4.0086505 | 0.003115137 | 2.50652282 |
| 3 | B Cells | ADAM9 | 1.921063e-01 | 0.7164585 | 0.961432818 | 0.01708106 |
| 4 | B Cells | ADGRE5 | 1.607047e-01 | 0.7939714 | 0.156413878 | 0.80572472 |
| 5 | B Cells | AIF1 | 6.393287e-01 | 0.1942758 | 0.101539719 | 0.99336404 |
| 6 | B Cells | ANKRD28 | 7.604660e-01 | 0.1189202 | 0.087858510 | 1.05621617 |
[ ]:
correlations <- pvalues_all %>%
group_by(celltype) %>%
summarize(
correlation = cor(minus_log10_pvalue_10x, minus_log10_pvalue_UCS, method = "pearson")
)
[ ]:
major_celltypes <- c(
"Invasive Tumor", "Stromal", "DCIS 1", "DCIS 2",
"Prolif Invasive Tumor", "Macrophages 1"
)
pvalues_all_major_celltype <- pvalues_all[pvalues_all$celltype %in% major_celltypes, ]
pvalues_all_major_celltype$celltype <- factor(
pvalues_all_major_celltype$celltype,
levels = sort(major_celltypes)
)
correlations_major_celltype <- correlations[correlations$celltype %in% major_celltypes, ]
p <- ggplot(
# pvalues_all,
pvalues_all_major_celltype,
aes(x = minus_log10_pvalue_10x, y = minus_log10_pvalue_UCS)
) + geom_point(aes(color = celltype), size = 5, alpha = 0.8) +
geom_abline(
intercept = 0, slope = 1,
linetype = "longdash", linewidth = 1.5
) + geom_text(
data = correlations_major_celltype,
mapping = aes(
x = 4, y = 15,
label = paste("r =", round(correlation, 2))
),
size = 5
) +
scale_x_continuous(limits = c(0, log10p_lim), oob = scales::oob_squish) +
scale_y_continuous(limits = c(0, log10p_lim), oob = scales::oob_squish) +
coord_fixed(ratio = 1) +
facet_wrap(~celltype, nrow = 1) +
theme_classic() +
labs(
x = "10x", y = "UCS",
title = expression(paste("-log"[10], plain(P), " from SPARK"))
) +
guides(color = guide_legend(nrow = 1)) +
theme(
plot.title = element_text(size = 20),
axis.title = element_text(size = 20),
axis.text.x = element_text(size = 20),
axis.text.y = element_text(size = 20),
strip.text = element_blank(),
legend.title = element_blank(),
legend.text = element_text(size = 18),
legend.position = "bottom"
)
ggsave(
filename = file.path(
RESULT_PATH,
paste0("SPARK_seg_comparison_oob_squish_", log10p_lim, ".pdf")),
plot = p, width = 12, height = 4
)
p

[ ]:
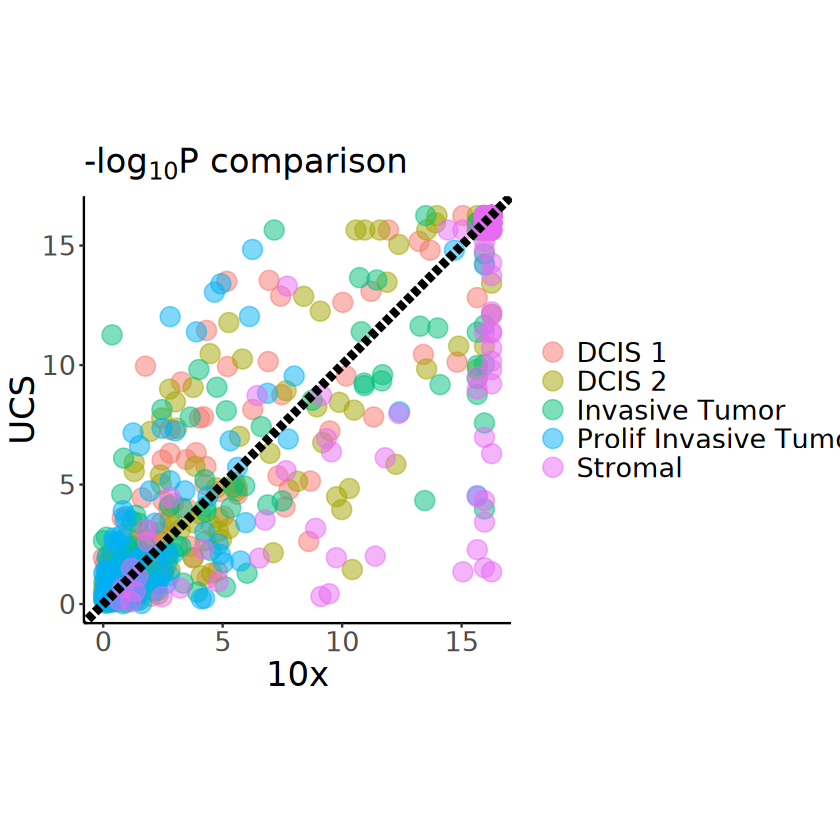
major_celltypes <- c("Invasive Tumor", "Stromal", "DCIS 1", "DCIS 2", "Prolif Invasive Tumor")
p <- ggplot(
pvalues_all[pvalues_all$celltype %in% major_celltypes, ],
aes(x = -log10(pvalue_10x), y = -log10(pvalue_UCS))
) +
geom_point(aes(color = celltype), size = 5, alpha = 0.5) +
geom_abline(
intercept = 0, slope = 1,
linetype = "longdash", linewidth = 2
) +
coord_fixed(ratio = 1) +
theme_classic() +
labs(
x = "10x", y = "UCS",
title = expression(paste("-log"[10], plain(P), " comparison"))
) +
theme(
plot.title = element_text(size = 20),
axis.title = element_text(size = 20),
axis.text.x = element_text(size = 16),
axis.text.y = element_text(size = 16),
legend.title = element_blank(),
legend.text = element_text(size = 16)
)
ggsave(
filename = file.path(RESULT_PATH, "SPARK_seg_comparison_together.pdf"),
plot = p, width = 8, height = 8
)
p
[ ]: